Survival of the Firstest: arXiv's positional effect on quant-ph citations
Wouldn’t it be weird if submitting a preprint to arXiv at a specific time of day led to more citations in the long term?
Position vs. citations
From my previous analysis: After a researcher first publishes a version of their article (a preprint) on the website arXiv, the preprint gets announced (via email and website) in a list containing recent submissions from other researchers doing similar work. But every list must have an order. ArXiv automatically orders preprints based on when they were submitted within a 24 hour submission window that starts at 2:00 PM Eastern. So, a not-small number of researchers end up timing their preprint submissions right at 2:00 PM so that their preprint goes to the top of the email list that appears in everybody’s inbox the next morning. This mechanism is pretty well known among the quantum physics community - certainly by hundreds, probably by thousands - and has been studied at an academic level [1, 2, 3, 4].
So what? Does timing a preprint submission accomplish anything for the author? This post is an attempt to figure that out. Assume that the typical researcher cares about their citation count - an imperfect-but-frequently-used proxy for research impact. Then we can look for a relationship between the number of citations that a preprint eventually receives versus the position of the preprint in its original email announcement. If we see such a relationship, then timing preprint submissions might just improve your citation count.
The dataset
We need a lot of data to see this effect. We’ll analyze the citation data for 16 years worth of submissions, corresponding to about 4000 submission windows containing 105,000 preprints. I emphasize “submission windows” and not “days”: The first window begins on Monday at 2:00 PM (all days/times are in Eastern time) and ends on Tuesday at 1:59:59 PM, followed by subsequent windows lasting 24 hours each until Friday at 2:00 PM, which marks the beginning of a 72 hour window (lasting until Monday afternoon) that otherwise obeys the same logic as the previous submission windows1. So a submission made on Sunday at 2:00:01 PM will not appear at the top of the list, it will appear near the bottom. This will be relevant later. The subsequent timing of announcement emails is kind of quirky, so just look at this diagram:
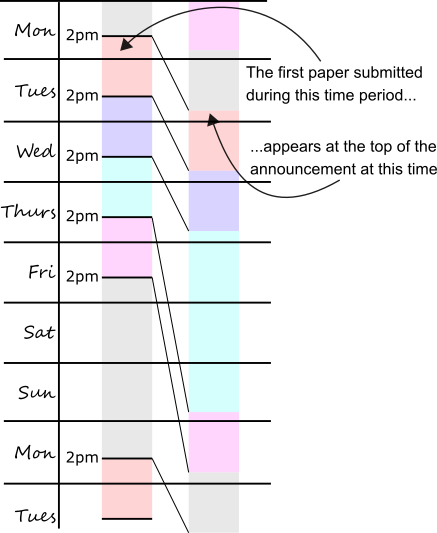
The submission windows and the subsequent ordering of submissions in (i) quant-ph email announcement and (ii) quant-ph/new. Notice how submissions on Wednesday stay up on that page for extra time.
The positional effect
Let’s look at how submission timing correlates with citation counts. The day of the week that you make a submission doesn’t matter much - except for weekend submissions, which tend to be cited slightly less. Overall, a surprising fraction of preprints are submitted between Friday afternoon and Monday afternoon, but of course timezones explain part of this (e.g. Monday morning in NYC is Monday night in East Asia). The Wed-Thurs submission window doesn’t receive extra citations, despite its announcement email being uncontested for the entire weekend.

The weekday that a preprint is submitted on doesn’t really correlate with citation count (mean (standard error) citations in red and median (IQ interval) in blue), but weekend submissions tend to be cited less.
On a finer level, the position of a submission within its respective submission window turns out to be correlated with citation count. We can see this by looking at the citation count as a function of each preprint’s position in the quant-ph arXiv announcement email. The effect is indeed obvious:
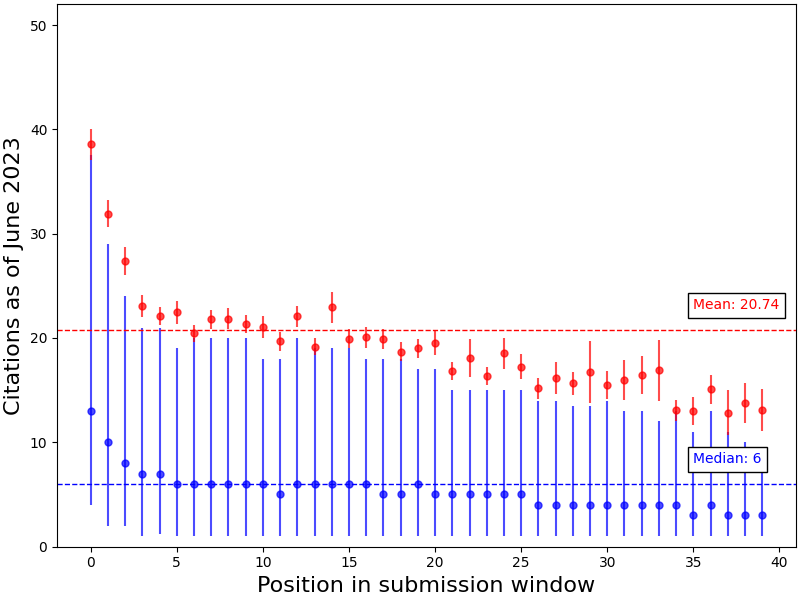
Mean (red) and median (blue) citations received by papers in each position both decrease for lower positions in the announcement email. In particular, a preprint appearing in the top five positions of their email announcement typically receives an above-average and above-median number of citations. Error bars correspond to standard error (red) and IQ range (blue).
[I want to emphasize how robust this effect is. It appeared in my initial analysis without any effort at data cleanup. It persists when I use a different citation database. And it appears in spite of time-dependent effects that should make it harder to see (e.g. I’m lumping together papers from 2007 with 15 years worth of citations with papers from 2022, I haven’t controlled for the total number of citations growing exponentially in time, etc).2]
Correlation, Causation
So far we have seen nothing that implies that a preprint’s position at the top of the arXiv mailing list causes that preprint to get more citations, i.e. we have not seen a causal relationship. Some underlying factor may be responsible for both high citation count and position in the list. Earlier work showed that preprints that appeared at the top of the list intentionally (by being submitted within minutes of 2:00 pm) received more citations than preprints that happened to appear at the top of the list (without the author actually attempting an timed submission)3. If we call the intentional ones earlybird submissions, then high citation counts for earlybird submissions is evidence against the causal relationship, since the citation count is partially explained by a hidden variable (e.g. the submitter’s intention to promote their submission) rather than position alone. From the data, we see that there is only weak evidence against the causal relationship. Namely the earlybird submissions perform better than submissions that unintentionally appeared first in the list, but both categories still exceed the typical citation count.

Separating out submissions by whether they were earlybird (EB) or non-EB, median citations for EB submissions are just slightly higher than median citations for non-EB submissions that happen to be 1st, 2nd, or 3rd - implying that its not just the position that causes higher citations. However, both categories still significantly outperform the median citation count (dashed line).
When I think about you I cite myself
Another test for a causal relationship is how strongly the excess citations depend on self-citation. Basically, a personality trait like “cares a lot about citations” could simultaneously explain submission timing along with other tendencies that tend to increase an authors citation count. In that case we expect to see a cluster of associated behaviors like self-citation or Twitter/Linkedin/ResearchGate activity and so on. Could the people submitting their preprints at the top of the list just be citing themselves a lot, and that explains why early bird submissions are more highly cited?4
This is not the case. Define self-citation as: some authors publish paper A and then any one of those authors writes paper B that cites paper A. Using INSPIRE-HEP5, we reproduce the earlier graph with and without self-citation. In the figure below, we see that controlling for self-citation does not affect the positional effect on citations.
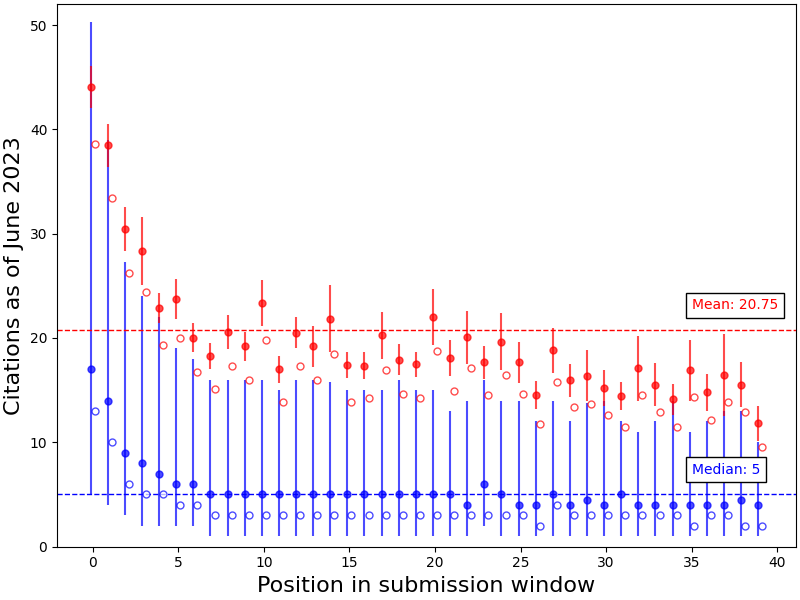
Controlling for self-citations does not change the positional effect of position on citation count (filled circles count all citations, empty circles count all citations minus self citations). The authors who do early bird submissions do not have any special tendency to inflate their own citation counts compared to others.
Wrong place, wrong time
Now we move from population analysis to case studies. I mentioned earlier that the submission window beginning on Friday at 2:00 PM is a special 72-hour-long one. But if you had heard from someone, “hey mumble mumble submit at 2:00 PM”, you might just do that on a Sunday afternoon, positioning your paper near the bottom of the announcement list. In the past 16 years, this seems to have happened on at least seven occasions6.
Beyond poetic justice, these mistakes also provide us with a test for a causal relationship between position and citations. Essentially, we can find examples of people who are ambitious or diligent enough to attempt placing their preprint at the top of the list, but then see what happens when the preprint instead appears close to the bottom of the announcement list. If that preprint goes on to receive many citations, then we can see that it was not the position of the preprint that actually mattered, but some other factor specific to that researcher or publication. Here’s how our seven subjects did:

Submitters who submitted at 2:00 PM (demonstrating intent to promote their paper) on a Saturday or Sunday (thereby landing far from the top of the list) tend to fare well. Red and blue lines correspond to mean and median citation counts from the first plot.
I think this shows more weak evidence against the causal relationship: Several papers published pretty low on the list still ended up receiving significant citations. Since the timing of the submissions demonstrates intent, the fact that these submissions were well-cited suggests that the intent to make the submission visible mattered more than its actual visibility in a list7: On the other hand, the criteria for determining whether a weekend submission was a mistake doesn’t work for authors with only a few submissions, and this is arguably a group with fewer citations per paper.
Conclusion
People who time their submissions to appear near the top of the announcement email are often the kind of people who would have been cited more regardless. But since papers that unintentionally appear near the top of the list still receive more-than-typical citation counts, its plausible that you can increase your citation count just by submitting preprints to arXiv at 2:00 PM Eastern time. But you won’t be without fierce competition. Sometimes a scene plays out in my head with a ticking clock showing 1:59 and four or five dudes across the world from each other are each hunched over their laptops with their mouse cursors hovering over the “submit” button, and the theme from the Good, the Bad, and the Ugly starts playing. This showdown, playing out daily among quant-ph researchers, hits harder when you realize that the long-term dissemination and recognition and implied quality of your scientific work is influenced by a few key seconds before you upload your preprint to arXiv. Its weird for this to just be a thing in an ostensibly objective field of academia. And its hard to see the justification for the continued existence of a system that works like this.
Aftermatter
Feel free to bring up any questions/comments on twitter.
Methodology, Limitations
I analyzed 105386 submissions to quant-ph between 2007-2023 (see here). Citation data are due to NASA ADS8 and INSPIRE-HEP. I rejected about 700 submissions for which the arXiv preprint appeared after a journal publication. I wrote an algorithm to reconstruct the placement of each arXiv submission in the daily email digest, controlling for daylight savings and drift in the submission deadline. I did not account for Holidays - there’s roughly 2 weeks worth of holidays according to arXiv, so this contributes an error of maybe 4% or so to the above plots. Nor did I account for disruptions to the typical order due to moderator intervention, which seems to work by placing papers at the top of the list for the next day after a moderation dispute was resolved. Figure 3 only depicts about 39,000 submissions, or 37%, of submissions considered here, due to INSPIRE-HEP’s limited quant-ph coverage.
Acknowledgements
Thanks to T. Rick Perche for suggesting the neat idea of looking into citations with/without self-citation. This research has made use of NASA’s Astrophysics Data System Bibliographic Services
-
Miscellanea: Once a year, the 72 hour weekend window becomes 71 or 73 hours due to daylight savings transition (always a Sunday in the USA). The submission cutoff has been 2:00 PM since 2017, but was actually at 4:00 PM before then. During specific holidays there is no arXiv announcement email and the submission window gets extended accordingly, sometimes by several days during Christmas break. These facts have been responsible immense confusion in the course of this analysis. ↩
-
I did not try to reproduce the effect in (Haque & Ginsparg, 2010) showing submissions at the end of a citation window received a citation boost. The proposed mechanism for that is based on quant-ph/recent being in reverse chronological order, while quant-ph/new is chronological. My bet is that this effect is very weak, especially since email lists get truncated for length - thereby omitting submissions in last place entirely - but this is on my TODO list. ↩
-
What I describe as surplus citations due to “intentional” (earlybird) submission is what Dietrich originally called “self-promotion (SP) bias”, in contrast with “visibility (V) bias” which describes surplus citations due to position alone. This suggests two categories of submissions to analyze citation data. However, I don’t fully grasp these categories: If self-promotion means intent to bring attention to a particularly strong paper, then the (SP) vs. (V) distinction makes sense. But if self-promotion involves just making the submission more visible to take advantage of the (V) bias (anecdotally, this is definitely what’s going on most of the time), then this submission should be categorized as (V) when analyzing citation statistics. Basically the categories (SP) and (V) are an overlapping Venn diagram, and checking submission times can only tell you that a submission is not in (SP). This is why I prefer “intentional” over using these categories. ↩
-
This is really two separate questions, and I’ve only addressed the second. The first question is messy. Total self citations is correlated with total early bird submissions, but both are also correlated with total submissions (early bird or not). Authors naturally accumulate self-citations as they publish more papers, and this is confounded by (a) INSPIRE-HEP has gaps in their coverage of citation data and (b) their method of counting self citations includes any author citing any other co-author, which blurs the effect we’re looking for. ↩
-
The two databases used here can disagree on citation counts by a lot. Its sometimes hard to know why. INSPIRE-HEP apparently only includes
quant-phsubmissions on a case-by-case basis, and only counts citations among papers it has already indexed. This tends to lead to undercounting of citations compared to ADS. But occasionally INSPIRE-HEP overcounts citations compared to ADS. One reason seems to be bibliographic errors: People cite things incorrectly all the time in a way that could confuse databases. A common example is something like a Nat. Commun. reference with no page number, an error that Google Scholar enthusiastically propagates. ↩ -
Here’s how I guess whether a paper was submitted at 2:00 PM on a weekend mistakenly by looking at the submitter’s habits. Among the set of submitters with one weekend earlybird submission, let n denote the submitter’s total submissions, and k denote the number of those that were earlybird. Define p=5/480 as the probability of randomly doing an earlybird submission over the course of an 8 hour workday, and so Bin(n, k, p) estimates the probability that this (n, k) combination occurred by chance. More intuitively: its pretty unlikely that someone submitted 9 papers and 3 of them were within 5 minutes of 2:00 PM by chance, so we suspect they were timing their submissions - implying that they mistakenly timed their weekend submission as well. While this probability might be close to 1-in-105,000 likely - and therefore expected to be observed in our dataset - this is actually a red herring since only a small fraction of all submitters have submitted 9 papers to the arXiv. Since there’s no more than a few hundred submitters with n>5, I pick p(mistake) < 10-4 as a threshold and find these candidates:
Subject n k p(mistake) 1 5 3 1.11 x 10-5 2 19 11 1.09 x 10-17 3 15 4 1.43 x 10-5 4 9 5 1.48 x 10-8 5 9 3 8.91 x 10-5 6 56 14 6.62 x 10-16 7 49 8 4.07 x 10-8 -
Another funny blooper is Europeans timing their submissions during that hard-to-remember 2-week period in March where Americans and European daylight savings times disagree, resulting in submissions from some Europeans that are precisely one hour late. ↩
-
The NASA ADS API has a query rate limit of 5000 per day with up to 2000 entries per query. You can get records for the complete dataset in 2 days using YYMM pattern matching on the arXiv identifiers, along with the extremely comforting fact that there are no more than 2000 quant-ph papers per month. ↩