The rising tide
Special thanks to Pangram for providing API credits to support this research!
Preface
I will first share an experience that you (a researcher, in 2026) might also have had. The rest of this post will show that it is statistically likely that you’ve had this experience, whether you know it or not.
I usually skim AI-generated text rather than actually reading it. Partly this is a defense mechanism: I have limited time and attention to read things, but nobody expends their limited time and attention to generate pure LLM text. Beyond this, AI writing usually lacks crystalline structure: at a high level it sounds fine, but upon careful reading the phrasing and sequences of words lack precision and conciseness. The parts of the text are lumped together amorphously, and the final product gives me brain fog if I attend to it with any real effort. It is like looking closer at a nice indoor plant and then noticing that it’s a fake: the leaves lack veins, the ribs are just colored in, the branches have an unnatural regularity.1
While I was recently reading the abstract of a preprint on arXiv, I felt this characteristic brain fog setting in right after reading “…identifies XXX not only as a YYY, but also as a ZZZ…”. A couple of online AI detection tools agreed with my suspicion that the abstract was entirely AI-generated.
This immediately raised the question: What fraction of quant-ph abstracts on arXiv are generated by AI, and how has that changed over time? Probably God only knows. In this post, we will rather answer the related question:
quant-ph abstracts on arXiv detected as AI-generated by AI detection software changed over time?
DISCLAIMER
AI detection software is not perfect. AI detection software can get things wrong: they are black box algorithms that cannot always provide reasoning to support their prediction. They can return false positives and negatives. They should be used responsibly - or perhaps not at all - for consequential decisions about scientific papers.
In that case, can we trust that an upwards trend in AI detection rates reflects an actual increase in AI usage? It might be that AI detection is useful for learning the statistics of AI-usage even if we do not fully trust the detectors on any particular input text. If so, we can consider two confounding reasons why the rate of AI-detection scientific preprints might increase over time:
-
Memorizing the training set: If pre-chatGPT arXiv were used as training data for AI detection software, this could give the illusion of a trend where there is none2. This is best explained by an example: if 2022 has a 0% detection rate and 2026 has a 50% detection rate, we could either conclude: (i) the rate of AI-generated abstracts increased from 0% to 50%, or (ii) the AI detector outputs “human” if the abstract was labelled as “human” in the training data, and otherwise outputs a coinflip. We will soon see that this explanation is not consistent with observed trends.
-
AI detectors might be low-quality: Another possibility is that AI detection software is uniformly unreliable. However, if we observe a trend in increasing AI detection rates, then attributing this trend to unreliability would require AI detection to become systematically less reliable specifically for recently-created text. This seems unlikely.
To summarize: If we see a gradual trend of increasing AI detection rates, this probably reflects an actual increase in AI usage over time.
All you zombies…
Below, we estimate the fraction of quant-ph abstracts detected as “100% AI-generated” by the popular AI-detector Pangram, from October 2022 (one month before ChatGPT) through April 2026.
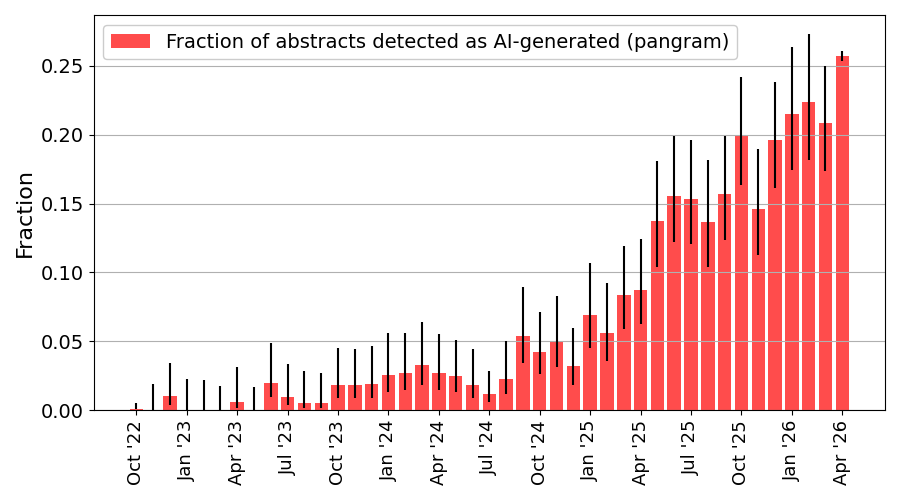
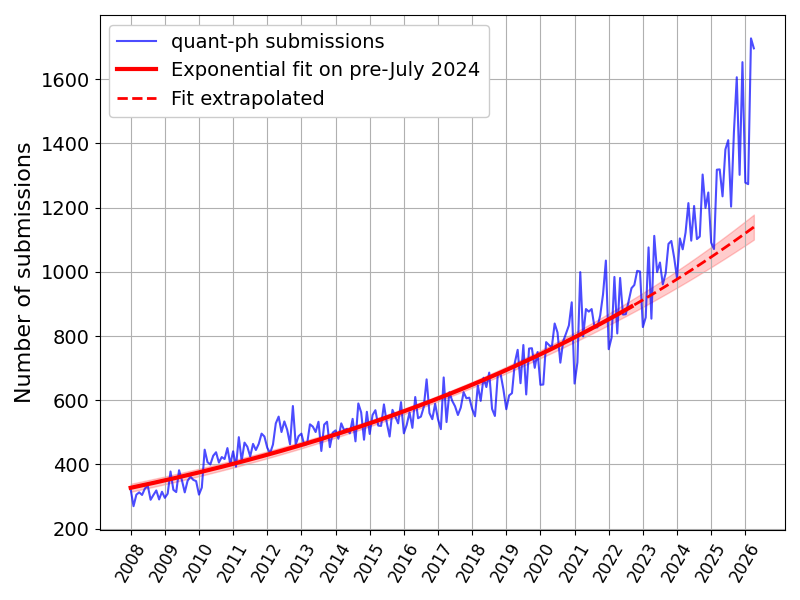
Clearly AI is now widely involved in the scientific writing process. To get a feel of how this translates to total submissions, here is a plot of monthly quant-ph submissions over a longer time span, with an exponential fit from 2008 to July 2024 (when the detection rate of AI-generated abstracts starts to rise3).
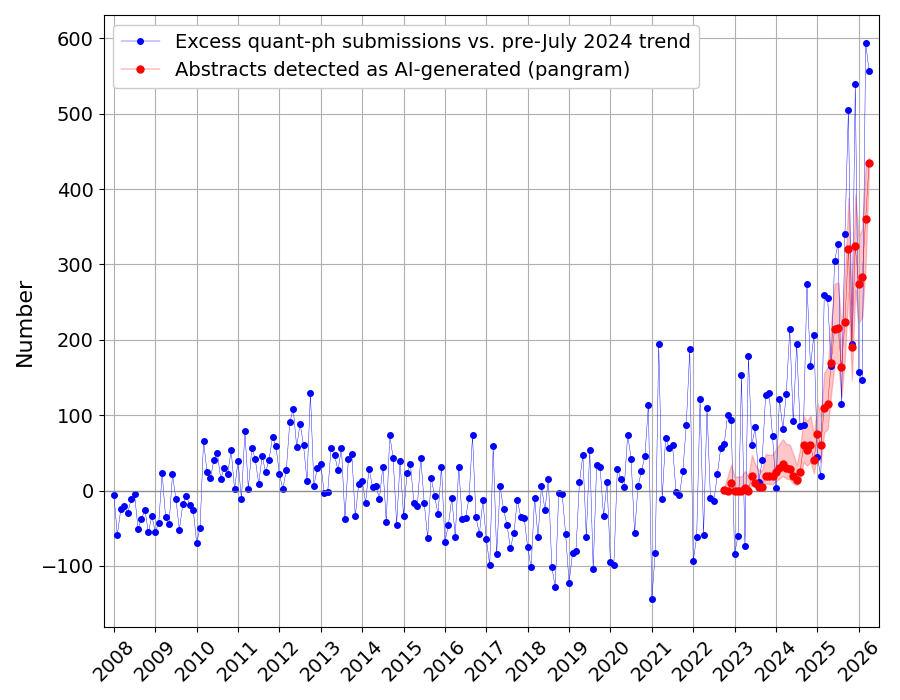
For a fun comparison, we can now overlay the estimated number of AI-detected abstracts (Fig. 1) onto the number of excess submissions (versus historical trends):
Among us
It would be nice if we could check how human scientists react to preprints with (purportedly) AI-generated abstracts. Scirate is a platform with an active user base of mostly quantum information researchers who upvote and comment on arXiv submissions. We can roughly think of preprints that receive many upvotes as being interesting or relevant to the community.
So, we can compare the upvotes for preprints with abstracts flagged as AI-generated versus human: If the distributions are similar, then the people giving upvotes are either unknowing or indifferent to whether the abstract was human-generated:
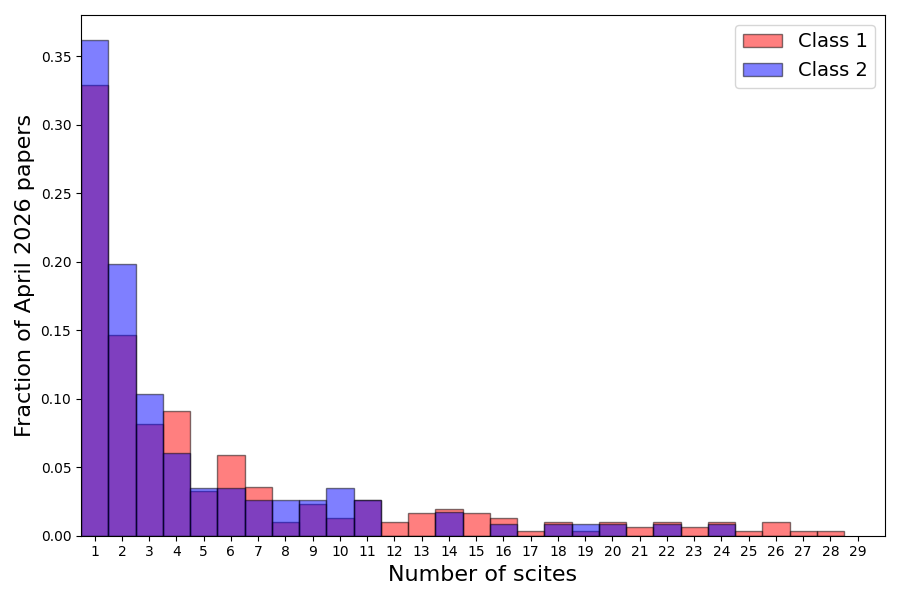
There are similar distributions of upvotes for preprints with abstracts detected as AI versus human. So the AI-generated science should not be thought of as some pile of junk hidden in the shadows, mass produced and written by no one and read by no one. Rather, it is among us.
Discussion
Things are moving fast. A few recent examples:
- In May, ArXiv announced a ban for author(s) who have submitted preprints with incontrovertible evidence of AI usage.
- In June, Neurips discussed desk-rejection of position paper submissions found to be substantially AI-generated.
Despite these interventions, in the near future you will be regularly and unknowingly be reading AI-generated text in your subfield. A substantial portion of the research itself (theory, numerics, original ideas) may even be AI-generated with only limited human supervision. We are now entering an era of Klankerphysik.
AI-generated text in research is not definitively bad. LLMs increase the rate at which we are able to share results (in the form of completed manuscripts), or improve the clarity of text from native and non-native English speakers alike. AI usage will lead to high-quality science and probably increase the progress of research at almost every level.
However, the incentives structures of research work are not adapted to this new way of doing science. Writing 10 papers in a year will now be only weak proof of significant effort, productivity, or accomplishment. Automatically-indexed citation counts and h-indices will be even weaker evidence of significance. Similarly, we will need better systems prevent us from wasting each other’s time. I do not want to serve as a referee for substantially AI-generated text (especially not for free). And you probably do not want your human-written submission refereed by an LLM. We will need to find balance.
Or perhaps this is a chance for a complete makeover on dissemination of science. Richard Hamming, who lived through and propelled widespread adoption of early scientific computing, wrote, “it has rarely proved practical to produce exactly the same product by machines as we produced by hand”4. Succinctly: If you don’t want to write an abstract, maybe just don’t!
Together we must decide on how to coexist with automated research.
Methods
-
For Figure 1, I analyzed (almost)5 all abstracts from April 2026 and October 2022, and then sampled roughly 20% of abstracts per month for all months in between. Abstracts were taken directly from the arXiv metadata set and were checked using the pangram API without any reformatting or cleanup. Cleaning up the special characters in a few example abstracts did not affect the AI prediction, though this may be an issue on a wider scale.
-
I reproduced part of Figure 1 using GPTZero’s AI detection software (~10% of all abstracts from November 2022 through March 2026, and ~99% of abstracts in October 2022 and April 2026). GPTZero detection showed a similar trend, while predicting a significantly larger fraction of AI-generated abstracts. This is consistent with reports that Pangram has a relatively low false-positive rate among available AI detectors.
-
For Figure 4 only, I used both pangram and GPTZero for AI detection on 1650 abstracts submitted in April 2026. I fetched scites (as of June 1) using Vincent Russo’s
scirateAPI. Pangram is more conservative in predicting that text is AI-generated:
| GPTZero: AI | GPTZero: Human | |
|---|---|---|
| Pangram: AI | 373 | 21 |
| Pangram: Human | 225 | 847 |
Acknowledgements
Huge thanks to Pangram for providing API credits to support this research. Thank you to Sasha Hrytseniak and Elies Gil-Fuster for feedback on earlier drafts of this post. Thank you to ArXiv for use of its open access interoperability. I used LLMs and agents for assistance gathering and analyzing the data presented above. I wrote 100% of the text in this post.
-
I believe that fake plants are an evil of modernity and that even beholding one drains a small part of one’s life essence from one’s body. ↩
-
I reached out to GPTZero and they would not provide any information about their training data. ↩
-
Alternatively, if we fit the trendline to pre-chatGPT (2008-2022) we get a shallower exponent. But since there does not seem to have been much AI usage before July 2024, the steeper trendline seems more appropriate. ↩
-
Hamming, Richard R. The Art of doing science and engineering: Learning to learn. Page 19. Stripe Press, 2020. ↩
-
There was a bug in my checkpoint code that saved API results after every 50 scans, combined with an off-by-one error from manually resetting data-taking runs. So I gathered 1650/1696 abstracts from April 2026 and 949/959 abstracts from October 2022. ↩