Is QEC eating quantum?
Quantum error correction (QEC) is a hot research topic among quantum computing researchers. This is a short analysis of just how popular QEC is.
QEC eats QCSE?
Quantum Computing Stack Exchange (QCSE) is a Q&A site for quantum information topics. Here we see a shift in interest towards QEC, as reflected by trends in QCSE question topics. Last month, for the first time ever, over half of the questions asked on QCSE were quantum error correction! Is evidence that interest in QEC displaced a broader curiousity about quantum computing?
Not really. Instead, the overall user base of QCSE is fleeing, while the number of QEC questions is holding strong. This is driven in part by a steady stream of questions about stim, a software library for simulating QEC whose creator - Craig Gidney - is very helpful and prolific on QCSE.
If we categorize questions according to their tag (indicates what the question topic is), we find a steep increase in QEC-related tags (left). But this hides a huge drop in the total number of user questions (right):
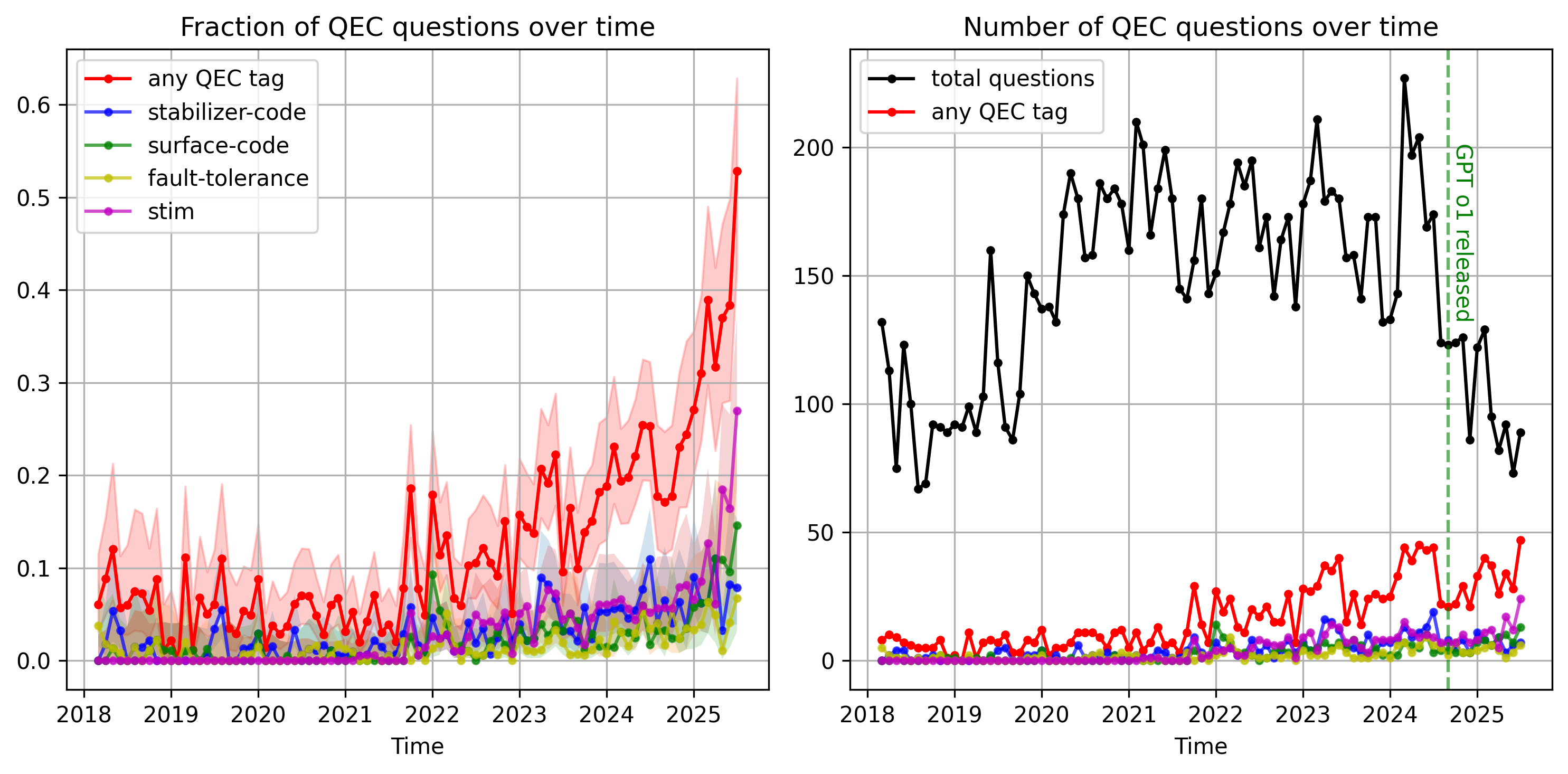
The drop in questions coincides with the o1 GPT model being released. This makes sense: Reasoning models are usually good at answering basic questions, and even more so when there is a lot of relevant source material available on the internet. But (right now), out-of-the-box AI chatbots are weak at coding tasks involving newer packages (e.g. there’s few code examples to scrape from stackoverflow). So the tag for stim (a popular but recent python package for QEC research) continues to go strong.
This is at least consistent with a trend in research interest towards QEC, but its indirect evidence since we can’t determine how the user base of QCSE divides among researchers versus a broader community of people interested in quantum. To focus on researchers specifically, we can take a look at the arXiv.
QEC eats quant-ph?
If we categorize every quant-ph arXiv submission according to keywords appearing in its abstract+title1, we can get a rough idea of trends in manuscript topics. After assembling a reasonable set of keywords (see Methods) for QEC-related submissions, and also preparing a set of keywords for “noisy intermediate scale quantum” (NISQ), we see this trend:
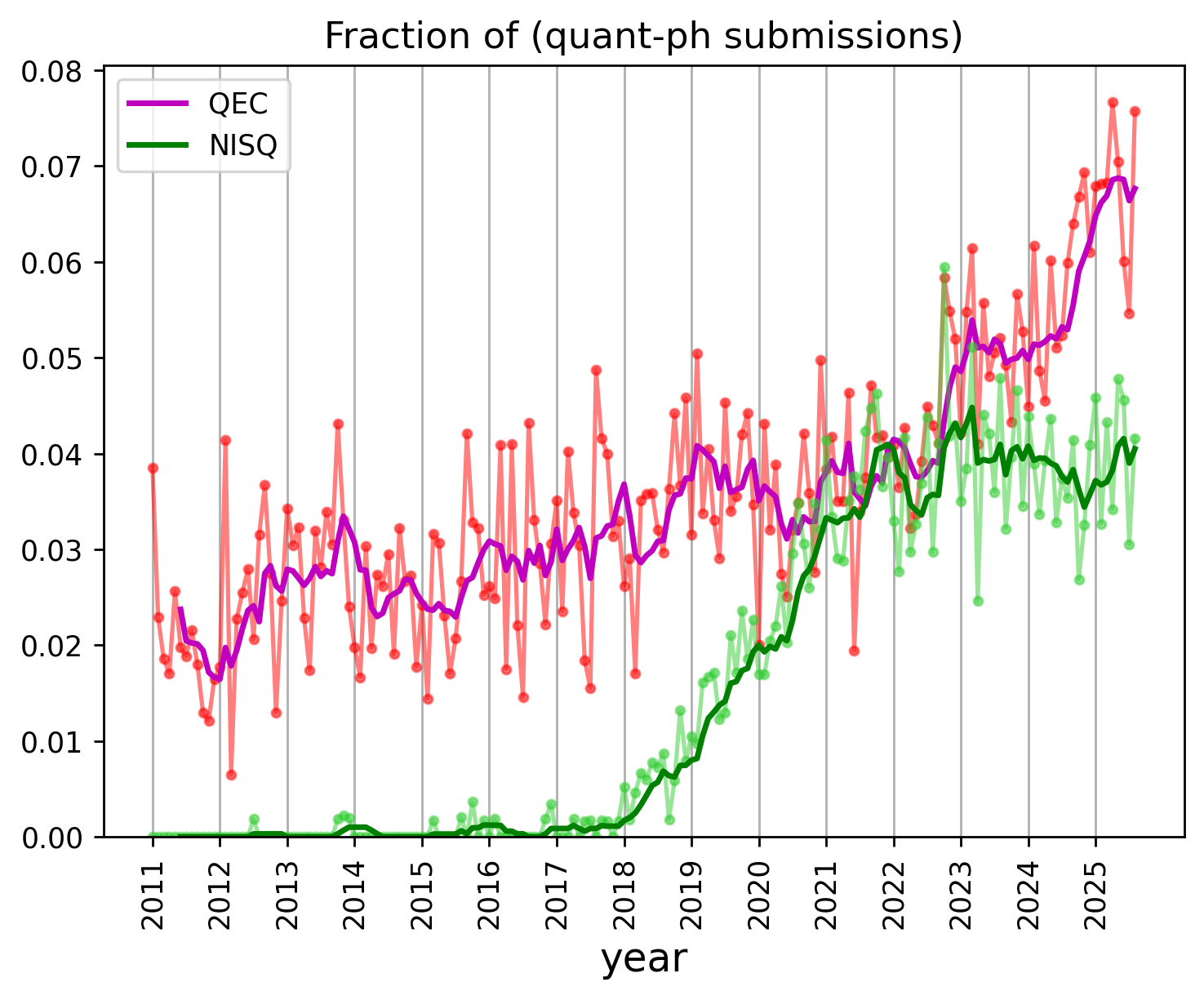
So, publication activity in the area of QEC and fault tolerance is blowing up super-exponentially (as evidenced by a sharp increase in the fraction of an already exponentially growing number of quant-ph submissions). Meanwhile, NISQ has lost a bit of steam (now what are we supposed to do with all these noisy uncorrected qubits?).
While counting quant-ph submissions is a decent proxy for what researchers are interested in and spending time on, it doesn’t tell us whether QEC is cool.
QEC eats Scirate?
Scirate is an online popularity contest platform that lets people upvote and comment on arXiv submissions. It is used almost exclusively by the quantum computing research community. Usage of scirate is growing rapidly, as the number of quant-ph submissions balloons beyond what is easily skimmable in a daily email2. I don’t really know what an upvote on Scirate means3, but to match the social media theme of the site, we will say a paper is cool if it gets a nontrivial number of upvotes on Scirate, and uncool otherwise4.
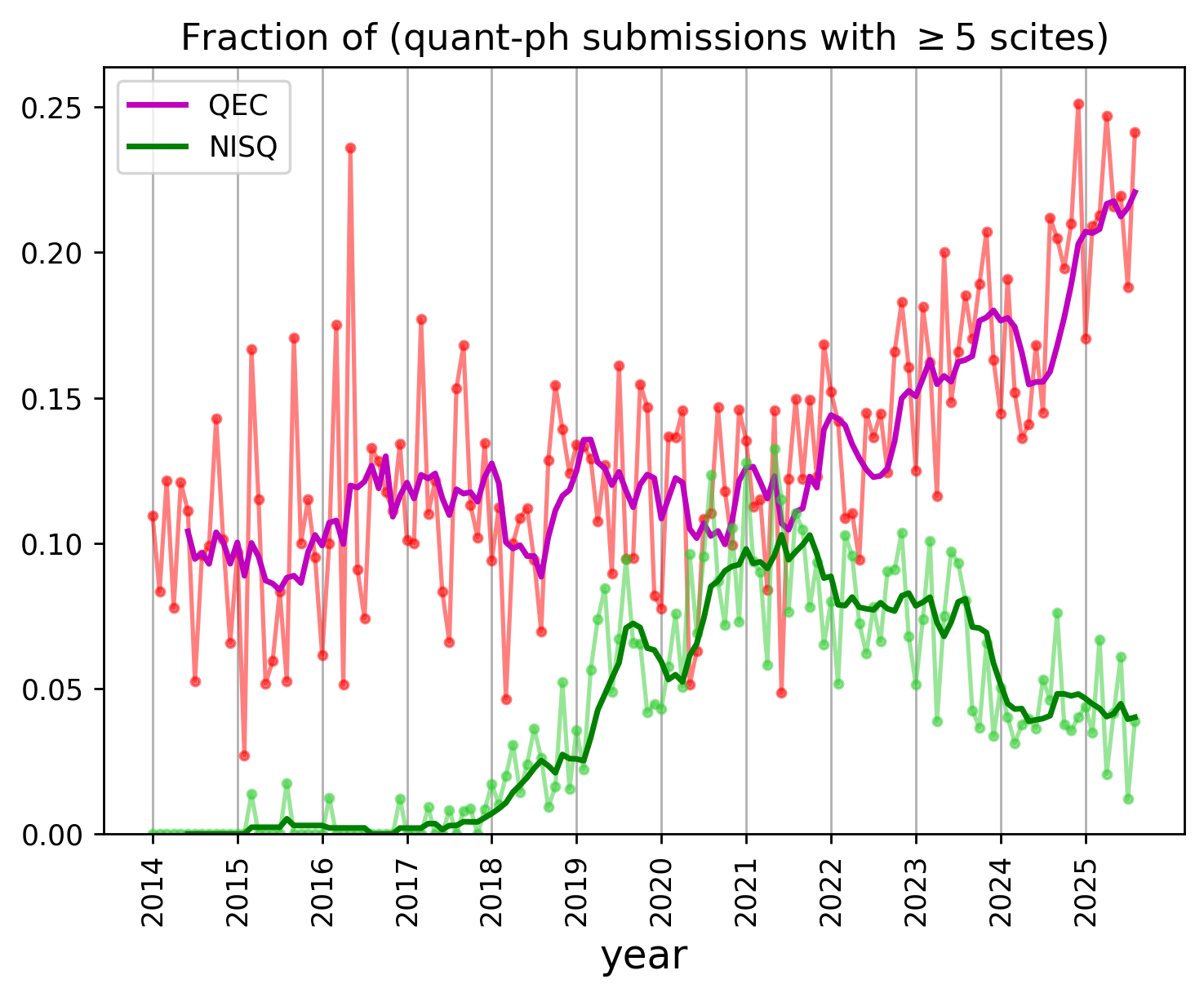
Here, we can see here that QEC-related manuscripts make up a growing fraction of cool submissions5. Furthermore, this analysis shows that NISQ publications are, in some sense, becoming less popular even as the number of publications holds steady6. There is an interesting disconnect between what the median researcher is willing to publish, versus what the median scirate user is willing to upvote.
Discussion
The clear takeaway is that QEC’s popularity is growing rapidly. In a way, this is both expected and healthy: we expect fault tolerance (FT) to be necessary for many of the promised speedups in quantum computing. NISQ was, in some ways, the idea that we could deliver useful quantum algorithms before building an FTQC, but the revealed preferences of the quantum community cast doubt on that idea.
We should perhaps keep an eye on this trend – there will come a day when we have FTQCs, and I hope that by then there is something useful to run on them. What balance is sustainable between efforts to get us to FTQCs versus finding tasks to do with FTQCs? For example, I imagine that classical error correction makes up a small fraction of computer science research today, though advancements in computing hardware are also an important source of progress. Which direction will QEC research go to remain relevant after quantum computers are already up and running?
Bonus: is QML cool or uncool?
Out of personal curiousity, I took a look at how QEC compares to another hot subfield, “quantum machine learning” (QML). Even with all the hype that QML has a (bad) reputation for, the growth rate for submissions in this subfield is actually lower than QEC in the same time period! But, as is clear from Scirate, QML papers make up a shrinking fraction of the cool papers, and again we see a disconnect between publishing activity and scirate popularity.
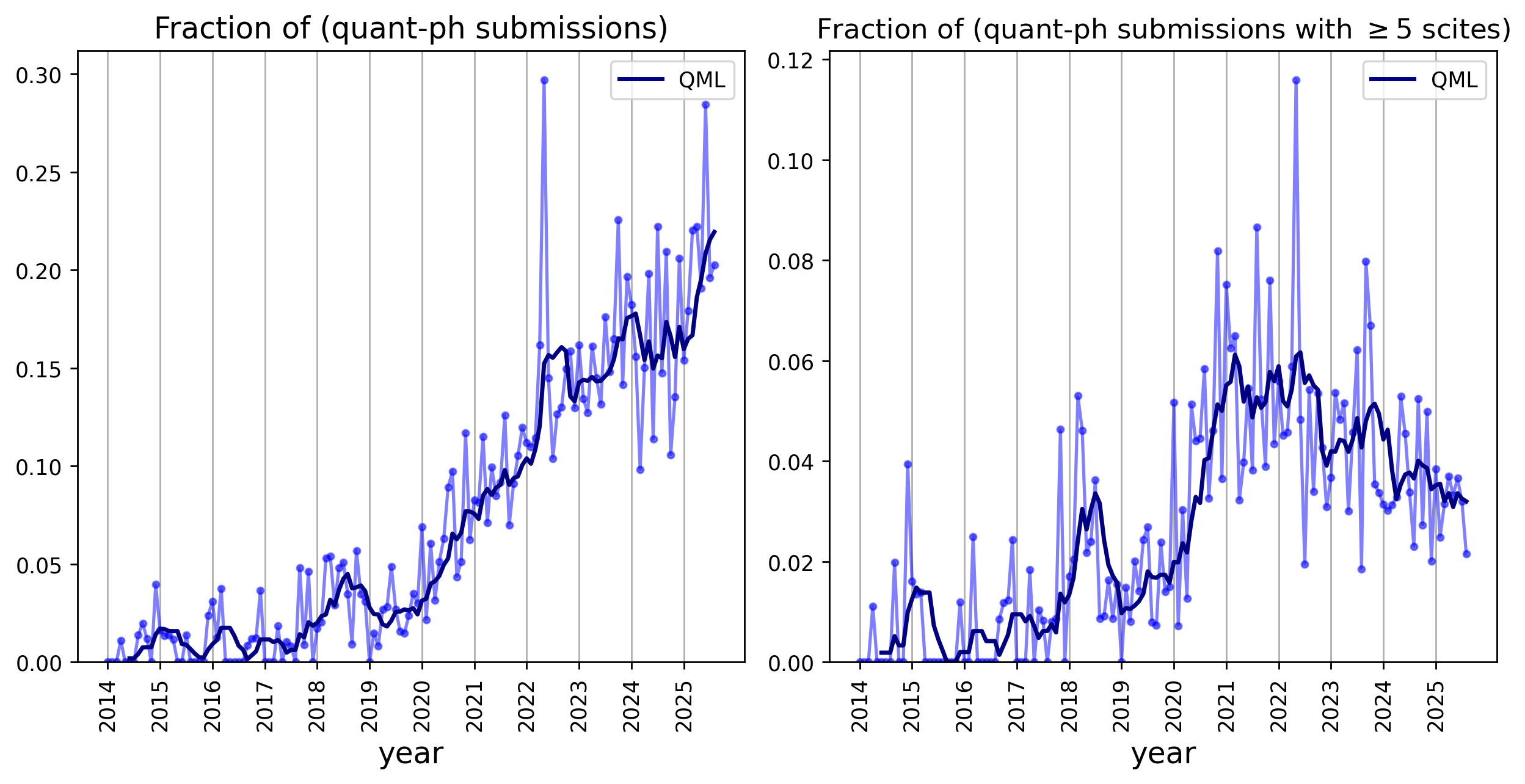
In contrast with NISQ, QML algorithms are often designed to run on FTQCs, so this is fall in popularity is rather damning. What would it take to make QML cool again?
Methods
The keywords for categorizing quant-ph submissions are below. Note that these lists are short, so the trend lines can be thought of as lower bounds. Obviously this is a fuzzy matching process and submissions can be cross-disciplinary, so treat these numbers as loose estimates.
QEC hits:
error correct: 3144
error-correct: 1152
logical qubit: 830
fault toleran: 475
stabilizer code: 510
surface code: 751
toric code: 475
qudit code: 11
error detect: 172
quantum code: 651
convolutional code: 40
CSS: 287
color code: 198
parity check: 133
logical gate: 242
logical error: 327
bicycle: 116
cubic code: 21
qec: 8
For NISQ, I’ve used the following barebones keywords. I have not included arguably-NISQ algorithms like VQE and QAOA, because those have sort of become subfields of their own and are not exclusively confined to NISQ devices.
NISQ hits:
intermediate scale: 256
hardware-efficient: 251
intermediate-scale: 1176
error mitigation: 647
nisq: 1424
hardware efficient: 41
zero-noise extrapolation: 70
For QML, I kept things straightforward but with the addition of “barren plateau”, which has a non-negligble effect on the overall trend.
QML hits:
qml: 374
quantum neural network: 564
quantum machine learning: 1265
barren plateau: 307
I used SEDE and ChatGPT for analyzing QCSE trends, the arXiv Kaggle dataset for quant-ph trends, and the scirate API for Scirate trends (so thanks to Vincent Russo).
-
The entire metadata for arXiv is available on Kaggle: link ↩
-
I mean this literally, in the sense that daily arXiv digest emails for
quant-phare now sometimes longer than the email length that gmail is willing to display by default, meaning that some submissions will not even appear in the email unless you exploit arXiv’s ordering system. ↩ -
Early on there was some debate among people using Scirate about what an upvote (scite) on scirate means, e.g. conversations here. I think the debate was never resolved, since I have no idea what a scite means. Whatever it means is probably not well thought out or deep. But I suspect that the median scientist is susceptible to social persuasion due to a reflexive-but-exagerrated belief in their own objectivity, so we should try to be careful how we react to seeing a bunch of upvotes on any particular article… ↩
-
This is tongue-in-cheek; of course don’t actually update your research tastes – or any tastes really – towards things that get ``likes’’ on social media. ↩
-
Its actually hard to do statistics on Scirate behavior, since upvotes are nonstationary (the average number of daily Scirate users grows over time) but also have very limited statistics (less than 50ish papers per day with large fluctuations). For example, comparing a submission’s scites to the average number of scites requires computing a moving average with a window that is small enough to reflect a roughly-stationary process but large enough to be meaningful. ↩
-
Alternative explanations: (1) The gross number of QEC researchers joining Scirate is higher than numbers of researchers in other fields. But this is why I set the threshold so low at 5 scites. (2) NISQ terminology is drifting over time, which is possible, but in some ways proves a similar point about the popularity of NISQ over time… ↩